
Controlling Search Engine Bots and Your Search Snippet with HTML
If you’re building a website, chances are at some point you want people to visit it! At the end of the day, you could have perfect HTML and CSS, but without a source of traffic, no-one will be there to enjoy it. Common traffic sources are
- Search Engines: Google, Bing, Yahoo, DuckDuckGo. This covers text search and voice searches that are powered by these engines.
- Social Media: which platforms are relevant to you are the ones you should use. There are a ton of Social Media networks even outside of the Facebooks and Twitters of this world.
- Other Websites: if you’re engaged in online communities, relevant groups, maybe a local business network, then they may have mentioned your brand or linked to your website.
- Direct Traffic: if people know your website’s URL, or you’ve handed out a leaflet or business card, or people have bookmarked your website, then you will get ‘direct traffic’.
I am going to deal with the first of these traffic sources and explain how you can control your search engine snippet and guide the bots to your content.
Jump To: How Bots Work – Meta Robots Tag – Per Link Control – Controlling Your Snippet
How A Search Engine Bot Works
Search engines like Google get sites into their index in multiple ways. Here are a few examples:
- You can submit your site to Google Search Console. A free tool, the Search Console allows you to submit an XML Sitemap and then in its own time Googlebot will visit the URLs in your sitemap and, if they think it’s relevant, add them to the search index.
- From links on your site and on other websites: When a search bot finds a link to a page, or an image, or a document, then they will ‘discover it’. And depending on other rules, they may make it into the index.
- From Social Media: public Social Media posts make a great source of links. And in 2015 Google got direct access to what is called Twitter’s firehose – a realtime list of Tweets. This means Tweets can end up in Google Search results and if those Tweets link to other websites, then Google can discover them.
So a search bot jumps from page-to-page, or document-to-document, via links. It reads your code, your dynamic content, your HTML tags and your content. Then if there’s a link there, it’ll move on to the thing being linked.
Deciding Which Pages Search Bots Can Index
If you don’t control your search bots, then any page or document that any search engine thinks is relevant can end up in their results. Why would you want some pages to not be in the search results? Here are some examples:
- A Member Login Screen
- A page which is hidden behind a paywall – premium content, online courses, membership systems etc.
- If you run a WordPress site then sometimes different ‘sections’ on page can have their own unique URL – template sections, custom post types and even individual media library items have an ‘attachment page’. You might want the images in the results, but not these ‘attachment pages’ which usually have little in the way of worthwhile content on them.
- A page you are still working on and don’t want the search engines to find until you’re ready.
- A new version of your website is in development but is not ‘live’ yet so you don’t want people to find it.
Thankfully you can decide which pages you want not to be indexed. This is achieved through this meta tag, which goes inside your <head> section:
<meta name="robots" content="index,follow">
This ‘meta robots’ tag takes two values separated by a comma. Here are valid combinations:
- index,follow: put this page into the search engine, then look for other links on this page to find.
- noindex,follow: don’t put this particular page into the results, but look for other links on this page.
- index,nofollow: put this page into your index, but don’t look for other links on this page.
- noindex,nofollow: don’t put this page into the search results and don’t look for other links on this apge.
It’s important to note that this is a suggestion that search engines usually honour. Google have said they may use ‘noindex’ to discover new URLs (via the follow directive).
However, you should use the <meta name="robots"> tag in your HTML to take as much control over the pages which can be found in the SERPs.
Controlling Search Bots Per Link
If you don’t want to have to control it on every page, you can control it per link. This mostly applies to links to other websites as you don’t really want to restrict search engine bots to your own content. However you can choose to nofollow a link to another site. Why would you do this?
- Links pass SEO Value, unless they have the ‘nofollow’ attribute. It’s against Google’s Webmaster Guidelines to have someone pay you to link on your site to theirs and and for that link to have ‘SEO Value’. So if someone’s paid you to do a piece of promotional content, that’s fine, but you don’t want to pass the value. If you’re receiving ad revenue from another company and that ad is a link to their website, that shouldn’t pass SEO Value.
- If you’re unsure of the quality of the site you’re linking to. Although to be honest in this case you really should just not bother linking to them! As a link is interpreted as you ‘vouching’ for the site, if you’re not 100% okay with that ‘vote’, then you can nofollow that link.
This is done as follows:
<a href="http://another.site/specific/page/" rel="nofollow">Another Site</a>
Note: nofollow will not prevent indexation, unless the target page has noindex in its meta robots tag!
Controlling Your Search Snippet
Another couple of features which are mostly in your control are the blue clickable-text in the search results and the summary information underneath that clickable text:
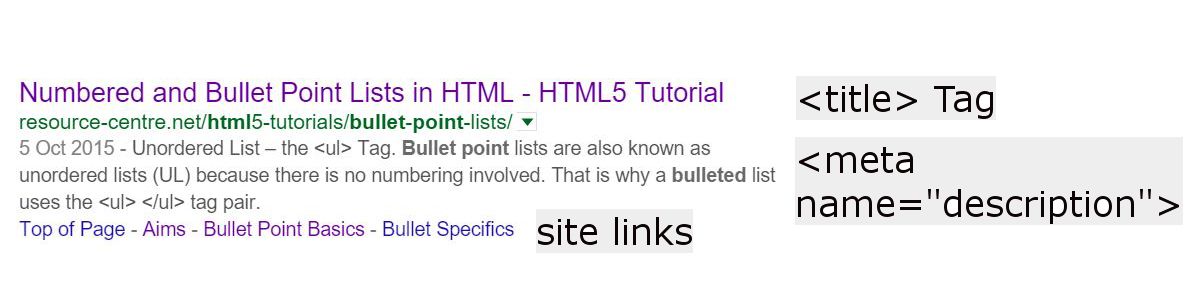
The <TITLE> Tag
The TITLE Tag governs, to some degree, the blue clickable text. However, Google can truncate what is visible if your TITLE Tag is too long in terms of pixel size (different letters and numbers take up different widths). Therefore as a guide try to keep your TITLE under 56 characters.
The META Description
The snippet underneath the blue link in the SERPs is called the meta description and is set using another tag within the <head> portion of your HTML Code:
<meta name="description" content="Learn how to control the pages of your site which appear in the search results by guiding search engine bots and how your page appears in the SERPS >>">
Again you should watch the length of this, so make it 156 characters or less and it shouldn’t get truncated. The META Description does not influence your search rankings but key words can be highlighted in bold, so make it relevant and useful to people searching. An enticing meta description can increase your Click-Through Rate (CTR), bringing you more traffic to your site.
Caution – Search Bots Have Their Own Mind
In both these tags, search engines may decide to ignore at their own whim! However, if you specify them, you have greater chance of your site appearing the way you want to in the search results.
Site Links
Site links appear at a search engine’s discretion. However you can influence what those are. The site links usually point to a Link Anchor somewhere on the page. From what I’ve seen it’s not sufficient for the anchors to exist – you need a link anchor which when clicked takes you to that part of the page.
<a href="#myanchor" title="My Sub-Section">My Sub-Section</a>
As I said there are no guarantees, but anchors can be helpful to your users regardless, so they can quickly get to the part of your page they are most interested in. When coding your website, put users first and anything else is a bonus!
TL;DR Controlling Search Engine Bots
This quick guide, as part of our HTML Tutorials is a quick start to controlling search engine bots and also how you appear in the search results. Every page should have a <title> tag and a meta description. And if you’re site is not showing up in the SERPs yet, then open a free Google Search Console account and submit a sitemap!
More HTML Tutorials
Spread the Word





